
[파이썬 머신러닝 완벽 가이드] 앙상블 (Ensemble)
앙상블
일종의 “머신러닝 집단지성”. 여러개의 분류기를 생성하고 예측 결과들을 결합하여 보다 정확한 최종 예측을 도출하는 알고리즘.
앙상블의 종류
- 보팅 (Voting)
- 배깅 (Bagging)
- 부스팅 (Boosting)
- 스태킹 (Stacking)
앙상블의 특징
- 단일 모델의 약점을 다수의 결합을 통해 보완
- 뛰어난 성능의 모델끼리 결합하는 것보다 상호보완이 되도록 서로 다른 유형의 모델들을 섞는 것이 오히려 도움이 될 수 있다.
- 랜덤 포레스트 및 다양한 부스팅 알고리즘은 의사결정 트리를 기반으로 하며, 앙상블을 통해 과적합을 보완하고 직관적인 분류 기준은 강화시킨다.
보팅 & 배깅
보팅과 배깅 둘 다 여러 분류기의 투표를 기반으로 예측 결과를 만들어 내는 앙상블 기법
보팅 (Voting) : 서로 다른 알고리즘의 분류기들을 결합하여 각 분류기들로부터 예측 결과를 받은 후 투표를 통해 최종 예측 값을 결정한다.
배깅 (Bagging) : 같은 유형의 알고리즘을 가진 분류기들을 사용하되 각각 다른 데이터셋을 기반으로 학습한 뒤 예측 결과를 투표하여 결정.
하드 보팅 vs. 소프트 보팅
-
하드 보팅 (Hard Voting) : 분류기 사이의 투표 결과에 따라 다수결로 최종 클래스를 결정
-
소프트 보팅 (Soft Voting) : 각 분류기가 예측한 클래스 확률을 모아 평균을 구한 뒤 가장 확률이 높은 클래스를 결정.
-
일반적으로 소프트 보팅이 더 많이 사용된다.
랜덤 포레스트 (Random Forest)
— 배깅을 사용하는 대표적인 알고리즘. 여러개의 의사결정 트리(나무)를 모아놓은 숲(Forest).
-
앙상블 알고리즘 중 비교적 빠른 수행 속도와 준수한 예측 성능을 보임
-
여러개의 결정 트리 분류기가 개별 학습 데이터셋을 사용하여 모델을 구축한 뒤 최종적으로 소프트 보팅을 통해 예측 결정을 진행한다.
※ 부트스트래핑 : 개별 학습 데이터셋 생성을 위해 전체 데이터에서 일부가 중첩되도록 샘플링을 하여 분리. (Bagging = Bootstrap Aggregating)
랜덤 포레스트 파라미터
트리 기반의 앙상블 알고리즘의 단점은 하이퍼 파라미터가 너무 많고 그로 인해 튜닝을 위한 시간이 많이 소모된다는 점이다. 게다가 튜닝에 사용하는 시간 대비 예측 성능이 크게 향상되는 경우가 많지 않다.
그나마 랜덤 포레스트는 결정 트리에서 사용되는 하이퍼 파라미터와 같은 파라미터가 대부분이라 파라미터가 적은 편에 속한다.
n_estimators
- 결정 트리의 개수를 지정
- 디폴트는 10개. 많이 설정할수록 좋은 성능을 기대할 수 있지만 학습 수행 시간이 오래 걸리며 성능이 무조건 향상되는 것은 아니다.
max_features
- 결정 트리의 max_features와 동일하지만 RandomForestClassifier의 디폴트는 ‘None’이 아니라 ‘auto’
부스팅
━ 여러개의 약한 학습기(Weak Learner)를 순차적으로 학습-예측 하면서 잘못 예측한 데이터에 가중치를 부여해가며 지속적으로 오류를 개선해나가는 앙상블 기법
-
성능은 좋지만 순차적으로 학습이 진행되기 때문에 시간이 오래걸리는 단점이 있다.
-
대표 부스팅 : 에이다 부스팅, GBM, XGBoost, LightGBM
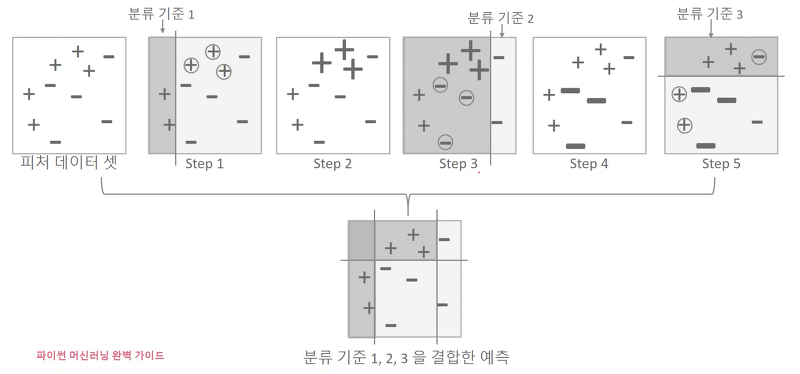
에이다 부스팅
학습-예측을 한 번 할 때마다 분류 기준을 생성하고 분류 결과가 맞지 않는 부분에 가중치를 두어 다음 학습-예측에서 해당 부분이 정확하게 분류되도록 한다. 그리고 이 과정을 반복하면서 만들어낸 분류 결과들을 결합하여 최종 예측 모델을 생성한다.
GBM (Gradient Boost Machine)
에이다 부스팅과 유사하나 가중치 업데이트에 경사하강법을 사용
GBM 주요 하이퍼 파라미터
- n_estimators, max_depth, max_features와 같은 트리 기반의 파라미터들이 마찬가지로 사용됨
- loss : 경사 하강법에서 사용할 비용함 수 지정. 기본값은 ‘deviance’
- learning_rate : GBM이 학습을 진행할 때마다 순차적으로 오류 값을 보정해 나가는 데 적용하는 계수.
- 0~1 사이의 값을 지정. 기본값은 0.1
- 작은 값을 적용할 경우 학습이 반복될 때마다 업데이트 되는 값이 작아져 최소 오류 값을 찾아 성능이 높아질 수 있지만 수행 시간이 오래 걸리고 또 너무 작게 설정할 경우 최소 오류 값을 찾기 전에 학습 반복이 완료될 수 있다.
- 반대로 너무 큰 값을 적용할 경우 수행 시간은 짧아지지만 최소 오류 값을 찾지 못하고 그냥 지나쳐 버려 예측 성능이 떨어질 수 있다.
- 위 특성 때문에 learning_rate는 n_estimator와 조합하여 상호 보완되도록 하는 것이 좋다.
- n_estimator : 학습기의 개수. 많을 수록 성능이 어느정도 좋아질 수 있지만 수행시간은 늘어난다. 기본값은 100
- subsample : 학습기가 학습에 사용하는 데이터의 샘플링 비율. 기본값은 1로 전체 학습 데이터를 기반으로 학습한다. 주로 과적합이 염려될 때 subsample을 1보다 작은 값으로 설정
XGBoost (eXtra Gradient Boost)
- 표준 GBM을 개선, 분류와 회귀에서 뛰어난 예측 성능을 보인다.
- CPU 병렬 처리 및 GPU 지원이 되어 GBM 대비 수행 시간이 빠르다.
- 규제(Regulation) 기능이 탑재되어 오차 오류만 계속 줄여 과적합이 생기는 것을 방지
- Tree Pruning(가지치기)를 통해 노드 검증을 진행하고 불필요한 노드를 제거할 수 있다.
- 편의 기능 : 조기 중단 (Early Stopping), 자체 내장 교차 검증, 결손값 자체 처리
- 조기 중단 : 학습 데이터를 가지고 너무 많은 반복을 하다보면 과적합이 발생하게 되는데, 특정 반복 횟수 이상 비용 함수가 감소하지 않으면 더 이상 학습을 반복하지 않도록 종료시켜준다.
※ XGBoost의 하이퍼 파라미터는 GBM과 유사하지만 파이썬 래퍼와 사이킷런 래퍼의 파라미터 명이 다르기 때문에 사용시 유의해야한다.
LightGBM
- XGBoost 이후 마이크로소프트가 개발
- XGBoost 대비 더 빠른 학습/예측 수행 시간과 더 작은 메모리 사용량을 보여준다.
- 카테고리형 피쳐 자동 변환과 최적 분할 지원 (원-핫 인코딩 없이도 자동 변환과 노드 분할 수행)
- 리프 중심 트리 분할 (Leaf Wise)
- 다른 부스팅은 결정 트리가 너무 한쪽 노드로 깊어지면 규칙이 복잡해지고 과적합이 생길 수 있다는 이론적 이유로 모든 노드가 균일한 depth를 갖는 균형 트리 분할 (Level Wise)을 사용해왔다.
- 하지만 LightGBM은 리프 중심의 트리 분할이 예측 오류를 가장 줄여줄 수 있다고 판단
※ LightGBM의 하이퍼 파라미터도 XGBoost의 하이퍼 파라미터와 유사하며 파이썬 래퍼와 사이킷런 래퍼의 파라미터 명 차이를 유의해야한다.
※ 또한 LightGBM은 리프 중심 트리 분할로 인해 리프 노드가 계속 분할되면서 트리의 깊이가 깊어지므로 해당 특성에 맞는 하이퍼 파라미터 설정이 필요하다.
스태킹
━ 앙상블과 비슷하나, 기반 모델들이 예측한 값들을 바탕으로 메타 모델을 만들어 다시 학습 후 예측을 반환한다.
개별 모델에 비해 반드시 성능 향상이 이루어지지는 않기 때문에 현실 모델에서는 잘 사용하지 않는다.
다만, 여러 모델들을 사용했을 때 더 좋은 결과를 만드는 경우가 있어서 캐글 같은 경연대회나 조금이라도 더 좋은 성능을 만들어내야만 하는 상황에 주로 사용된다.
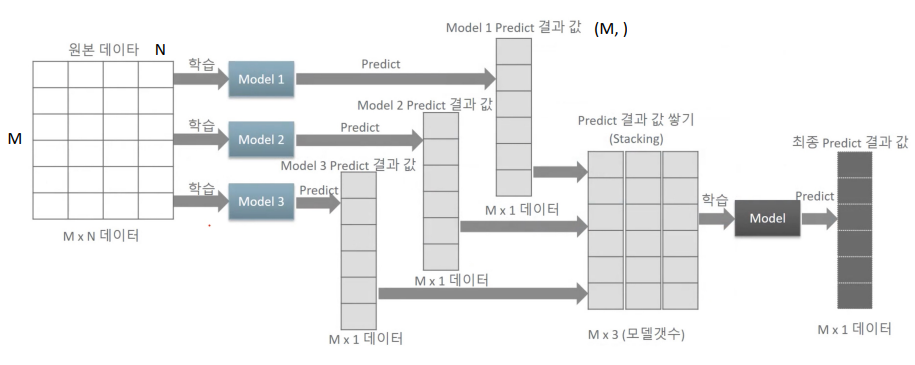
Basic Stacking Model
- 예측 결과들을 쌓아서(Stacking) 다시 학습 데이터로 사용. 이 때 transpose를 필요로 한다.
- Basic Stacking Model 은 개념적 모델이며 실질적으로는 과적합이 일어나기 때문에 교차검증 스태킹을 사용한다.
교차검증 스태킹
- 각 기반 모델들에서 KFold 교차검증을 실행하여 검증 결과와 테스트 결과를 도출한다.
- 도출된 검증 결과들은 스태킹을 통해 메타 모델의 학습 데이터로 사용하고, 테스트 결과들은 스태킹하여 메타 모델의 테스트 데이터로 사용하여 메타 모델을 구축한다.
댓글남기기